
Page 69 - DMGT209_QUANTITATIVE_TECHNIQUES_II
P. 69
Quantitative Techniques-II
Notes Conclusion: Half of the population has income> 21568' and half of the population has income
< 21568.
Mean
In a grouped data, the midpoint of each category would be multiplied by the number of
observation in that category. Sum up and the total to be divided by the total number of observation.
fx
Eqn., X =
f
Example: 2 students X, Y attend 3 classes tests and the scores areas follows:
Though Mean is same, X is better than Y.
Measures of Dispersion
rd
nd
st
Marks 1 Test 2 Test 3 Test Mean
X 55% 60% 65% 60%
Y 65% 60% 55% 60%
Conclusion X - has improved
Y - has Deteriorated
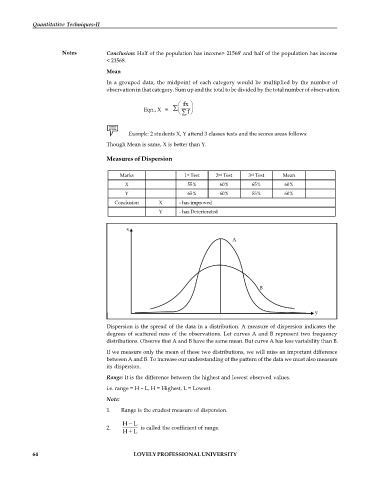
Dispersion is the spread of the data in a distribution. A measure of dispersion indicates the
degrees of scattered ness of the observations. Let curves A and B represent two frequency
distributions. Observe that A and B have the same mean. But curve A has less variability than B.
If we measure only the mean of these two distributions, we will miss an important difference
between A and B. To increase our understanding of the pattern of the data we must also measure
its dispersion.
Range: It is the difference between the highest and lowest observed values.
i.e. range = H – L, H = Highest, L = Lowest.
Note:
1. Range is the crudest measure of dispersion.
H L
2. is called the coefficient of range.
H + L
64 LOVELY PROFESSIONAL UNIVERSITY