
Page 165 - DCAP606_BUSINESS_INTELLIGENCE
P. 165
Business Intelligence
Notes
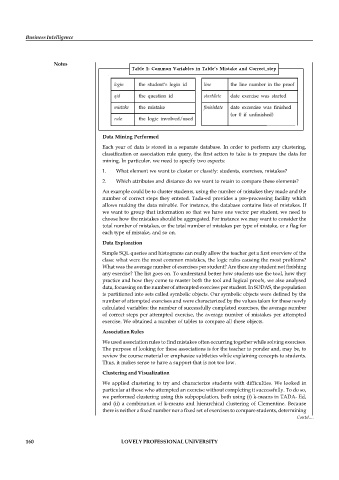
Table 1: Common Variables in Table’s Mistake and Correct_step
Data Mining Performed
Each year of data is stored in a separate database. In order to perform any clustering,
classification or association rule query, the first action to take is to prepare the data for
mining. In particular, we need to specify two aspects:
1. What element we want to cluster or classify: students, exercises, mistakes?
2. Which attributes and distance do we want to retain to compare these elements?
An example could be to cluster students, using the number of mistakes they made and the
number of correct steps they entered. Tada-ed provides a pre-processing facility which
allows making the data minable. For instance, the database contains lists of mistakes. If
we want to group that information so that we have one vector per student, we need to
choose how the mistakes should be aggregated. For instance we may want to consider the
total number of mistakes, or the total number of mistakes per type of mistake, or a flag for
each type of mistake, and so on.
Data Exploration
Simple SQL queries and histograms can really allow the teacher get a first overview of the
class: what were the most common mistakes, the logic rules causing the most problems?
What was the average number of exercises per student? Are there any student not finishing
any exercise? The list goes on. To understand better how students use the tool, how they
practice and how they come to master both the tool and logical proofs, we also analysed
data, focussing on the number of attempted exercises per student. In SODAS, the population
is partitioned into sets called symbolic objects. Our symbolic objects were defined by the
number of attempted exercises and were characterized by the values taken for these newly
calculated variables: the number of successfully completed exercises, the average number
of correct steps per attempted exercise, the average number of mistakes per attempted
exercise. We obtained a number of tables to compare all these objects.
Association Rules
We used association rules to find mistakes often occurring together while solving exercises.
The purpose of looking for these associations is for the teacher to ponder and, may be, to
review the course material or emphasize subtleties while explaining concepts to students.
Thus, it makes sense to have a support that is not too low.
Clustering and Visualization
We applied clustering to try and characterize students with difficulties. We looked in
particular at those who attempted an exercise without completing it successfully. To do so,
we performed clustering using this subpopulation, both using (i) k-means in TADA- Ed,
and (ii) a combination of k-means and hierarchical clustering of Clementine. Because
there is neither a fixed number nor a fixed set of exercises to compare students, determining
Contd....
160 LOVELY PROFESSIONAL UNIVERSITY