
Page 166 - DCAP208_Management Support Systems
P. 166
Unit 10: Data Mining Tools and Techniques
You could create even more training records than 10 by creating a new record starting at every Notes
data point. For instance you could take the first 10 data points and create a record. Then you
could take the 10 consecutive data points starting at the second data point, then the 10 consecutive
data point starting at the third data point. Even though some of the data points would overlap
from one record to the next the prediction value would always be different. In our example of
100 initial data points 90 different training records could be created this way as opposed to the
10 training records created via the other method.
Why Voting is Better – K Nearest Neighbors
One of the improvements that is usually made to the basic nearest neighbor algorithm is to take
a vote from the “K” nearest neighbors rather than just relying on the sole nearest neighbor to
the unclassified record.
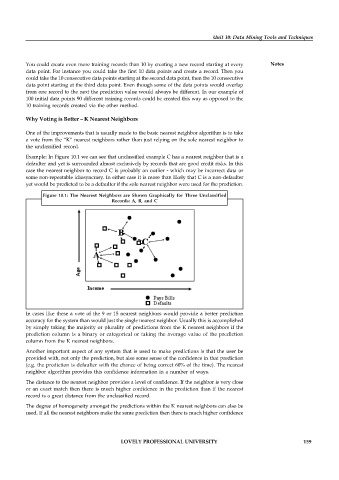
Example: In Figure 10.1 we can see that unclassified example C has a nearest neighbor that is a
defaulter and yet is surrounded almost exclusively by records that are good credit risks. In this
case the nearest neighbor to record C is probably an outlier - which may be incorrect data or
some non-repeatable idiosyncrasy. In either case it is more than likely that C is a non-defaulter
yet would be predicted to be a defaulter if the sole nearest neighbor were used for the prediction.
Figure 10.1: The Nearest Neighbors are Shown Graphically for Three Unclassified
Records: A, B, and C
In cases like these a vote of the 9 or 15 nearest neighbors would provide a better prediction
accuracy for the system than would just the single nearest neighbor. Usually this is accomplished
by simply taking the majority or plurality of predictions from the K nearest neighbors if the
prediction column is a binary or categorical or taking the average value of the prediction
column from the K nearest neighbors.
Another important aspect of any system that is used to make predictions is that the user be
provided with, not only the prediction, but also some sense of the confidence in that prediction
(e.g. the prediction is defaulter with the chance of being correct 60% of the time). The nearest
neighbor algorithm provides this confidence information in a number of ways.
The distance to the nearest neighbor provides a level of confidence. If the neighbor is very close
or an exact match then there is much higher confidence in the prediction than if the nearest
record is a great distance from the unclassified record.
The degree of homogeneity amongst the predictions within the K nearest neighbors can also be
used. If all the nearest neighbors make the same prediction then there is much higher confidence
LOVELY PROFESSIONAL UNIVERSITY 159