
Page 167 - DCAP208_Management Support Systems
P. 167
Management Support Systems
Notes in the prediction than if half the records made one prediction and the other half made another
prediction.
10.2.3 Clustering
Clustering is the method by which like records are grouped together. Usually this is done to
give the end user a high level view of what is going on in the database. Clustering is sometimes
used to mean segmentation – which most marketing people will tell you is useful for coming up
with a birds eye view of the business. Two of these clustering systems are the PRIZM™ system
from Claritas corporation and MicroVision™ from Equifax corporation. These companies have
grouped the population by demographic information into segments that they believe are useful
for direct marketing and sales. To build these groupings they use information such as income,
age, occupation, housing and race collect in the US Census. Then they assign memorable
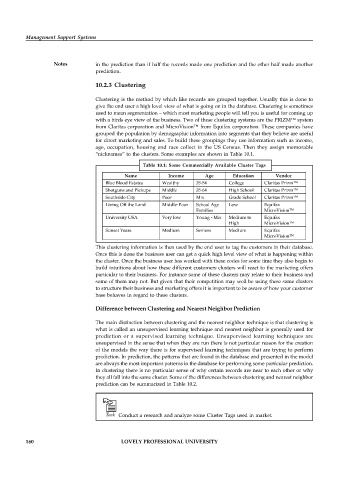
“nicknames” to the clusters. Some examples are shown in Table 10.1.
Table 10.1: Some Commercially Available Cluster Tags
Name Income Age Education Vendor
Blue Blood Estates Wealthy 35-54 College Claritas Prizm™
Shotguns and Pickups Middle 35-64 High School Claritas Prizm™
Southside City Poor Mix Grade School Claritas Prizm™
Living Off the Land Middle-Poor School Age Low Equifax
Families MicroVision™
University USA Very low Young - Mix Medium to Equifax
High MicroVision™
Sunset Years Medium Seniors Medium Equifax
MicroVision™
This clustering information is then used by the end user to tag the customers in their database.
Once this is done the business user can get a quick high level view of what is happening within
the cluster. Once the business user has worked with these codes for some time they also begin to
build intuitions about how these different customers clusters will react to the marketing offers
particular to their business. For instance some of these clusters may relate to their business and
some of them may not. But given that their competition may well be using these same clusters
to structure their business and marketing offers it is important to be aware of how your customer
base behaves in regard to these clusters.
Difference between Clustering and Nearest Neighbor Prediction
The main distinction between clustering and the nearest neighbor technique is that clustering is
what is called an unsupervised learning technique and nearest neighbor is generally used for
prediction or a supervised learning technique. Unsupervised learning techniques are
unsupervised in the sense that when they are run there is not particular reason for the creation
of the models the way there is for supervised learning techniques that are trying to perform
prediction. In prediction, the patterns that are found in the database and presented in the model
are always the most important patterns in the database for performing some particular prediction.
In clustering there is no particular sense of why certain records are near to each other or why
they all fall into the same cluster. Some of the differences between clustering and nearest neighbor
prediction can be summarized in Table 10.2.
Task Conduct a research and analyze some Cluster Tags used in market.
160 LOVELY PROFESSIONAL UNIVERSITY