
Page 66 - DCAP603_DATAWARE_HOUSING_AND_DATAMINING
P. 66
Data Warehousing and Data Mining
notes
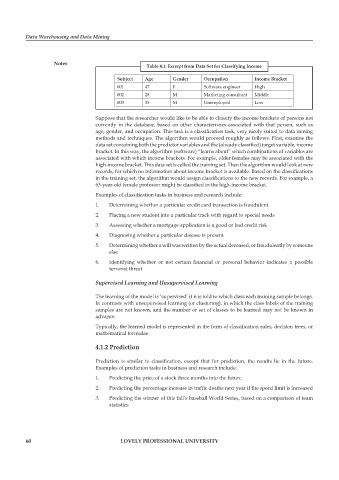
table 4.1: excerpt from Data set for classifying income
subject age gender occupation income Bracket
001 47 F Software engineer High
002 28 M Marketing consultant Middle
003 35 M Unemployed Low
Suppose that the researcher would like to be able to classify the income brackets of persons not
currently in the database, based on other characteristics associated with that person, such as
age, gender, and occupation. This task is a classification task, very nicely suited to data mining
methods and techniques. The algorithm would proceed roughly as follows. First, examine the
data set containing both the predictor variables and the (already classified) target variable, income
bracket. In this way, the algorithm (software) “learns about” which combinations of variables are
associated with which income brackets. For example, older females may be associated with the
high-income bracket. This data set is called the training set. Then the algorithm would look at new
records, for which no information about income bracket is available. Based on the classifications
in the training set, the algorithm would assign classifications to the new records. For example, a
63-year-old female professor might be classified in the high-income bracket.
Examples of classification tasks in business and research include:
1. Determining whether a particular credit card transaction is fraudulent
2. Placing a new student into a particular track with regard to special needs
3. Assessing whether a mortgage application is a good or bad credit risk
4. Diagnosing whether a particular disease is present
5. Determining whether a will was written by the actual deceased, or fraudulently by someone
else
6. Identifying whether or not certain financial or personal behavior indicates a possible
terrorist threat
Supervised Learning and Unsupervised Learning
The learning of the model is ‘supervised’ if it is told to which class each training sample belongs.
In contrasts with unsupervised learning (or clustering), in which the class labels of the training
samples are not known, and the number or set of classes to be learned may not be known in
advance.
Typically, the learned model is represented in the form of classification rules, decision trees, or
mathematical formulae.
4.1.2 prediction
Prediction is similar to classification, except that for prediction, the results lie in the future.
Examples of prediction tasks in business and research include:
1. Predicting the price of a stock three months into the future
2. Predicting the percentage increase in traffic deaths next year if the speed limit is increased
3. Predicting the winner of this fall’s baseball World Series, based on a comparison of team
statistics
60 LoveLy professionaL university